Rick Gallaher, CISSP, is owner of Dragonfly Associates LLC http://dragonfly-associates.

In previous articles, we discussed data flow, signaling, and rapid recovery. This article addresses the subject of traffic engineering.
Vocabulary:
- Silence Suppression: Not using bandwidth when there is no data to send.
- CR-LDP: Constraint Route Label Distribution Protocol.
- Over-provisioning: Having more bandwidth than allocated traffic.
- Over-subscribing: Having more allocated traffic than available bandwidth. (Telco)
- RSVP-TE: Resource Reservation Setup Protocol with Traffic Engineering
- Under-subscribing: Having more bandwidth than allocated traffic. (Telco)
- Under-provisioning: Having more allocated traffic than available bandwidth.
There is a road in Seattle, Washington that I drove years ago called Interstate 5. From the suburb of Lynnwood, I could get on the highway and drive into the city, getting off at any exit. If I wanted to go from Lynnwood into the heart of Seattle, I could get onto the express lanes. This express lane is like an MPLS tunnel. If my driving characteristics matched the requirements of the express lane, then I could use it.

Figure 5.1: Express Lane
It would be nice to have traffic report, but traffic reports are not given in real time – by the time that I would find out about a slowdown, I would be stuck in it. I could make the mistake of entering the express lane just as an accident happens 5 miles ahead and be trapped for hours.
It would be great if I had a police escort. The police would drive in front of me; if there were an accident or a slowdown, then they would take me on a detour of similar quality to ensure that I arrive at my destination on time.
On the Internet, we have thousands of data roads just like Interstate 5. With MPLS, we have a road dedicated to traffic with certain characteristics – much like the express lane. To ensure that the express lane is available and free of congestion, we can use protocols like CR-LDP and RSVP-TE. These protocols are discussed in greater detail in the article Advanced MPLS Signaling. Currently, the most popular of these two protocols appears to be RSVP-TE, because it acts like a police escort to ensure that, if there is congestion, it can be re-routed around the problem area.
When looking at traffic patterns around the country, often freeways experience congestion and delays, while other roads are open and allow traffic to flow freely. The traffic is just in the wrong area. Wouldn’t it be nice if the highway engineers and the city planners could find ways to route heavy traffic to roads that could handle the traffic load and to adjust the road capacity as needed to accommodate traffic volume?
Traffic Engineering
In data and voice networks, traffic engineering is used to direct traffic to the available resources. If achieving a smooth-flowing network by moving traffic around were simple, then our networks would never experience slowdowns or rush hours.
On the Internet (as with highways), there are four steps that must be undertaken to achieve traffic engineering: measuring, characterizing, modeling, and moving traffic to its desired location.

Figure 5.2: Four Aspects of Traffic Engineering
Measuring traffic is a process of collecting network metrics, such as the number of packets, the size of packets, packets traveling during the peak busy hour, traffic trends, applications most used, and performance data (i.e., downloading and processing speeds).
Characterizing traffic is a process that takes raw data and breaks it into different categories so that it can be statistically modeled. Here, the data that is gathered in the measurement stage is sorted and categorized.
Modeling traffic is a process of using all the traffic characteristics and the statistically analyzed traffic to derive repeatable formulas and algorithms from the data. When traffic has been mathematically modeled, different scenarios can be run against the traffic patterns. For instance, “What happens if voice/streaming traffic grows by two percent a month for four months?” Once traffic is correctly modeled, then simulation software can be used to look at traffic under differing conditions.
Putting traffic where you want it: To measure, characterize, and model traffic for the entire Internet is an immense task that would require resources far in excess of those at our disposal. Before MPLS was implemented, we had to understand the characteristics and the traffic models of the entire Internet in order to perform traffic engineering.
When addressing MPLS traffic engineering, articles and white papers tend to focus on only one aspect of traffic engineering. For example, you may read an article about traffic engineering that addresses only signaling protocols or one that just talks about modeling; however, in order to perform true traffic engineering, all four aspects must be thoroughly considered.
With the advent of MPLS, we no longer have to worry about the traffic on all of the highways in the world. We don’t even have to worry about the traffic on Interstate 5. We just need to be concerned about the traffic in our express lane – our MPLS tunnel. If we create several tunnels, then we need to engineer the traffic for each tunnel.
Provisioning and Subscribing
Before looking at the simplified math processes for engineering traffic in an MPLS tunnel, a brief discussion of bandwidth provisioning and subscribing is needed.
First, let’s look at the definitions. Over-provisioningis the engineering process in which there are greater bandwidth resources than there is network demand. Under-provisioning is the engineering process in which there is greater demand than there are available resources. “Provisioning” is a term typically used in datacom language.
In telecom language, the term “subscribe” is used instead of “provision.” Over-subscribing is the process of having more demand than bandwidth, while under-subscribing is a process of having more bandwidth than demand. It is important to note that provisioning terms and subscription terms refer to opposite circumstances.
A pipe/path/circuit that has a defined bandwidth (e.g., a “Cat-5” cable) can in theory process 100 Mb/s, while an OC-12 can process 622 Mb/s. These are bits crossing the pipe and comprise all overhead and payload bits.
In order to determine the data throughput at any given stage, you can measure the data traveling through a pipe with relative accuracy by using networking-measurement tools. Using an alternate measurement method, you can calculate necessary bandwidth by calculating the total payload bits per second and adding the overhead bits per second; this second method is more difficult to calculate and less accurate than actually measuring the pipe.
If the OC-12, which is designed to handle 622 Mb/s, is fully provisioned and the traffic placed on the circuit is less than 622 Mb/s, it is said to be over-provisioned. By over-provisioning a circuit, true Quality of Service (QoS) has a better chance of becoming a reality; however, the cost per performance is significantly higher.
If the traffic that is placed on the OC-12 is greater than 622 Mb/s, then it is said to be under-provisioned. For example, commercial airlines under-provision as a matter of course, because they calculate that 10-15% of their customers will not show up for a flight. By under-provisioning, the airlines are assured of full flights; but they run into problems when all the booked passengers show up for a flight. The same is true for network engineering – if a path is under-provisioned, then there is a probability that there will be a problem of too much traffic. The advantage of under-provisioning is a significant cost savings; the disadvantages are loss of QoS and reliability.

Figure 5-3: Over-Provisioning v. Under-Provisioning

Figure 5-4: Comparison of Over Provisioning and Under Provisioning
Calculating How Much Bandwidth You Need
For the sake of discussion in these examples, let’s assume that you know the characteristics of your network. This is a process of gathering data that is unique to your situation and has been measured by your team.
Example One: Two tunnels with load balanced OC-12 designed for peak busy hour.
Let’s say that we want to engineer traffic for an OC-12 pipe, which is 622 Mbps.
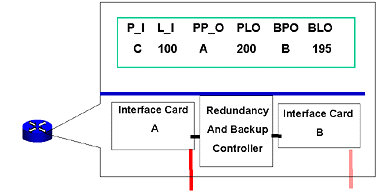
You want to have rapid recovery, so you use two pipes and load balance each pipe for 45% of capacity. In this case, if one OC-12 pipe fails, then your rapid recovery protocol can move traffic from your under-provisioned pipe to the other, and the total utilization is still under-provisioned.

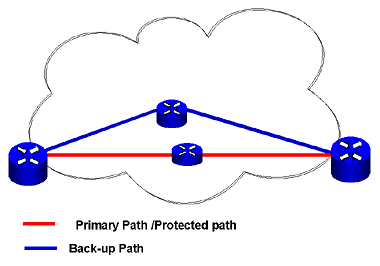
Figure 5-5: Sample Network Diagram Example One

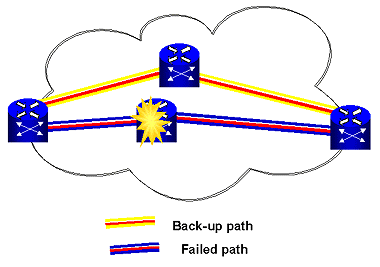
Figure 5-6: Sample Network Failure

Figure 5-7 Traffic Trends
We can work these numbers just like we would in a checkbook. After we do the math, if we still have money (bits) remaining, then we are okay. If our checkbook comes out in the red, then we must go back and budget our spending.The following table helps to simplify the bandwidth budgeting process, as well as demonstrate some of the calculations involved in traffic engineering.Our traffic trends for peak busy hour show that we have:
| Traffic Demands | Totals and subtotals | ||
| Number of voice calls | 100 | ||
| b/s/call | 200,000 | ||
| Total voice streams in b/s | 20,000,000 | 20,000,000 | |
| Number of video calls | 3 | ||
| b/s/call | 500,000 | ||
| Total video streams in b/s | 1,500,000 | 1,500,000 | |
| Committed information rate | 250,000,000 | 250,000,000 | |
| Other traffic | 0 | 0 | |
| Total traffic demand | 271,500,000 | 271,500,000 | BW required |
| Bandwidth Available | |||
| Circuit bandwidth for OC-12 | 622,000,000 | ||
| Percentage used | 45% | Over- provisioned | |
| Total BW for over-provisioned | 279,900,000 | 279,900,000 | BW on-hand |
| 271,500,000 | BW required | ||
| Remaining Bandwidth | 8,400,000 | BW remaining | |
| Key BW = Bandwidth b/s = bits per second b/s/call = bits per second for each call | |||
Figure 5-8: Traffic Engineering Calculations for Example One
Now that we understand the basic concept, let’s play with the figures a bit to achieve the outcomes that we need.
Example 2: Example with Silence Suppression
First, let’s say that we are going to use “silence suppression” on the voice calls. Silence suppression means that we will not use bandwidth if we are not transmitting. The effects of silence suppression can be seen in Figure 5-9 below, which is a simple 10 count over 10 seconds.
The lows in the graph indicate the periods in which no data is being sent. Silence suppression can be used if the calls have the characteristics of phone calls (Figure 5-9). However, if the calls are streaming voice like a radio show, or piped-in music (Figure 5-10), notice that the baseline is higher, and that more overall bandwidth is used.

Figure 5-9: Voice with Silence Suppression

Figure 5-10: Music Jazz (The Andrews Sisters singing “Boogie-Woogie Bugle Boy”)
| Traffic Demands | Totals and subtotals | ||
| Number of voice calls | 100 | ||
| b/s/call | 100,000 | ||
| Total voice streams in b/s | 10,000,000 | 10,000,000 | |
| Number of video calls | 3 | ||
| b/s/call | 500,000 | ||
| Total video streams in b/s | 1,500,000 | 1,500,000 | |
| Committed information rate | 250,000,000 | 250,000,000 | |
| Other traffic | 0 | 0 | |
| Total traffic demand | 261,500,000 | 261,500,000 | BW required |
| Bandwidth Available | |||
| Circuit bandwidth for | 622,000,000 | ||
| Percentage used | 45% | Over- provisioned | |
| Total BW for over-provisioned | 279,900,000 | 279,900,000 | BW on-hand |
| 261,500,000 | BW required | ||
| Remaining Bandwidth | 18,400,000 | BW remaining | |
| Key BW = Bandwidth b/s = bits per second b/s/call = bits per second for each call | |||
Figure 5-11: Traffic Engineering Calculations for Example Two
Example 3: Over Provisioned by 110%
Many carriers will choose over-provisioning because they cannot afford the cost of designing a highway system for rush hour traffic. Instead, they design a network for “normal traffic.” Over-provisioning a network is similar to the airlines overbooking flights. There is a statistical point at which possible loss of customers is less than the cost of running planes at half capacity.
Let’s use the same example as above, with no switchable path and an OC-12 pipe that is able to tolerate some congestion during rush hour. We choose not to design the tunnel for peak busy-hour traffic; instead we design it for 10% over-provisioning, or 110% of the available bandwidth.
On paper this looks great, as we can still handle several hundred more calls, and it is an accountant’s dream. However, trouble lies in wait. What happens if all of the traffic arrives at the same time? In addition, how can we handle a switchover to another link? If this link is provisioned at 110%, and the spare link is provisioned at 110%, one link will have a 220% workload during a single link failure, and will more than likely fail itself.
| Traffic Demands | Totals and subtotals | ||
| Number of voice calls | 100 | ||
| b/s/call | 100,000 | ||
| Total voice streams in b/s | 10,000,000 | 10,000,000 | |
| Number of video calls | 3 | ||
| b/s/call | 500,000 | ||
| Total video streams in b/s | 1,500,000 | 1,500,000 | |
| Committed information rate | 250,000,000 | 250,000,000 | |
| Other traffic | 0 | 0 | |
| Total traffic demand | 261,500,000 | 261,500,000 | BW required |
| Bandwidth Available | |||
| Circuit bandwidth for OC-12 | 622,000,000 | ||
| Percentage used | 110% | Over- provisioned | |
| Total BW for over-provisioned | 684,200,000 | 684,200,000 | BW on-hand |
| 261,500,000 | BW required | ||
| Remaining Bandwidth | 422,700,000 | BW remaining | |
| Key BW = Bandwidth b/s = bits per second b/s/call = bits per second for each call | |||
Figure 5-12: Traffic Engineering Calculations for Example Three
Summary
Traffic engineering for MPLS consists of four elements: measurement, characterization, modeling, and putting traffic where you want it to be. MPLS can use either traffic engineering protocols (CR-LDP or RSVP-TE) discussed in advanced signaling to put traffic where it is desired. Of the two protocols, RSVP-TE appears to be more dominant, but it costs more in bandwidth – it is like paying for a police escort when you travel.
The rest of traffic engineering is far from simple. You must measure, characterize, and model the traffic that you want. Once you have the information that you need, you can then perform mathematical calculations to determine how much traffic can be placed on your tunnel.
The mathematical process is like balancing a checkbook; you should never allow the balance to go into the red or negative area.
The tradeoff decisions are difficult to make. Can you over-provision (over-book) your tunnel and just hope that rush hour traffic never comes your way? In the event of a failure, where is the traffic going to go?
Suggested URLs:
| Traffic Modeling http://www.comsoc.org/ci/public/preview/roberts.html |
| Draft Math RFC http://www.ietf.org/internet-drafts/draft-kompella-tewg-bw-acct-00.txt |
| Bell Labs http://cm.bell-labs.com/cm/ms/departments/sia/InternetTraffic/ |
| Traffic Engineering Work Group http://www.ietf.org/html.charters/tewg-charter.html |
| Inside the Internet Statistics http://www.nlanr.net/NA/tutorial.html |
| Excellent Measurement Site http://www.caida.org/ |
| Modeling and Simulation Software HTTP://NetCracker.Com |
Special Thanks
I would like to thank Ben Gallaher, Susan Gallaher, and Amy Quinn for their assistance in reviewing, and editing this article.
A special thank you to all those who assisted me with information and research on the MPLSRC-OP mail list, especially: Senthil Ayyasamy, Irwin Lazar, and Ashwin C. Prabhu.
Rick Gallaher, CISSP, is owner of Dragonfly Associates LLC http://dragonfly-associates.com
Rick is also the author of Rick Gallaher's MPLS Training Guide - Building Multi Protocol Label Switching Networks