By Raghu Kondapalli, Director of Strategic Planning at LSI
This is the second article in a two-part series. The first article, which discussed the drivers, benefits and trends of unified datacenter-carrier networks, and introduced SDN and NFV technology, is available here.
This article provides some examples of how SDN and NFV can be applied to various segments of a carrier network, and how the functions of a traditional carrier network can be offloaded to a virtualized datacenter to improve end-to-end performance.
In addition to these well-known protocol-level techniques, network-level abstraction based on SDN similarly enables the integration of datacenter and carrier networks. Here are two examples.
Offloading of network control functions to a centralized datacenter using SDN
Control plane components, such as discovery and dissemination of network state, can be decoupled and executed in a centralized datacenter using commodity servers. Centralizing the control plane has the advantage of providing an end-to-end network state view, and enables the network operator to allocate hardware resource pools based on different application needs. Centralizing the control plane also enables the network operator to use standard APIs to monitor and manage the network, and to provision the network according to changing conditions, such as the number of active subscribers.
Offloading of network application software to a virtualized datacenter using SDN
SDN’s centralized control platform for managing hardware resources also supports the virtualization and execution of core applications in one or more datacenters. For a “software-on-demand” capability, for example, a network operator could designate core application software to run on any hardware platform in any datacenter that provides the required processing capacity. Or to provide LTE services in a certain city, the operator might program serving gateway (SGW) or mobility management entity (MME) software to run on a local platform. A major benefit of having network services being fully abstracted is that the operator need not manage the underlying hardware.

 Applying virtualization schemes based on SDN and NFV enables the entire carrier network to run on a common, commodity and multi-purpose hardware resource pool. This reduces network cost and complexity significantly, which also simplifies network management. By leveraging centralized control and virtualized hardware platforms, core applications share a common hardware pool that improves both scalability and resource utilization. The use of virtualized resource pools can also enable new services and upgrades to be implemented in many cases without costly hardware upgrades.
Applying virtualization schemes based on SDN and NFV enables the entire carrier network to run on a common, commodity and multi-purpose hardware resource pool. This reduces network cost and complexity significantly, which also simplifies network management. By leveraging centralized control and virtualized hardware platforms, core applications share a common hardware pool that improves both scalability and resource utilization. The use of virtualized resource pools can also enable new services and upgrades to be implemented in many cases without costly hardware upgrades.
Figure 7 shows a conceptual view of the SDN-based carrier network. Note how the hardware platform is decoupled from the software platform, and how this enables different cellular technologies to run as virtualized network elements concurrently and independently of any specific hardware platform.
Consider, for example, an SGW that forwards packets and an MME that is responsible for activation or authentication in an LTE network. Because these functions are typically executed on common and proprietary hardware platforms, they are visible to one another, resulting in management, resource sharing and security problems. Abstraction with SDN enables the use of commodity hardware, while also mitigating the management, resource sharing and security issues.
Another example is shown in Figure 8. In this example, dedicated application software, which implements network functions for each dedicated core network element like MME or Gateway and Serving GPRS Support Nodes (GGSN and SGSN), can be virtualized and centralized with SDN to run in a private cloud, on virtualized commercial server platforms, or on multi-vendor, non-proprietary hardware.

 Under an SDN architecture, basestation pools with high-bandwidth, low-latency interconnects can be centralized to form virtualized “basestation clouds.” A centralized control plane, which has a global view of all physical processing resources throughout the cloud, enables network operators to program basestation processing tasks for different standards. For example, operators can deploy 3G or 4G RANs by programming different virtual basestations, and then adjust the capacity of each, all through software reconfigurations.
Under an SDN architecture, basestation pools with high-bandwidth, low-latency interconnects can be centralized to form virtualized “basestation clouds.” A centralized control plane, which has a global view of all physical processing resources throughout the cloud, enables network operators to program basestation processing tasks for different standards. For example, operators can deploy 3G or 4G RANs by programming different virtual basestations, and then adjust the capacity of each, all through software reconfigurations.
Figure 10 shows an implementation of such a “Cloud-based RAN” (C-RAN) architecture that has been proposed by China Mobile (CMCC). The wireless remote radios connect to a cloud-based, virtualized basestation cluster, which can be implemented using SDN running on heterogeneous hardware processors.

SDN is able to combine these different networking technologies in a way that leverages their respective strengths; in the example above, the simplicity of static network routing is combined with the flexibility and economic advantages of IP. This is possible because SDN decouples the network control and traffic-forwarding functions, thereby eliminating any interdependencies. For this reason, a distributed transport network element is able to support both static routes and dynamic traffic flows.
Summary
The telecommunications industry today, fueled by exploding growth in mobile subscribers and data usage, is undergoing an unprecedented transformation. As a result, service providers are under enormous pressure to deploy new value-added services while lowering costs to remain competitive. To achieve these objectives, carriers are integrating datacenters into their networks to create a more versatile and affordable unified datacenter-carrier network model.
Service providers also need to increase average revenue per user (ARPU) while reducing capital and operational expenditures through hardware consolidation, network resource optimization and ease-of-service deployment. Virtualization is a proven technology that has been adopted universally in datacenters to enhance resource utilization and scalability. By extending virtualization principles to the carrier infrastructure, service providers can optimize the unified datacenter-carrier network end-to-end and top-to-bottom.
Software-defined Networking and Network Function Virtualization enable this versatility in all three segments of a carrier network. SDN enables network functions and applications to leverage virtualized datacenter resources, while a combination of SDN and NFV enables carriers to deploy and scale innovative services more cost-effectively than ever before.
 Raghu Kondapalli is director of technology focused on Strategic Planning and Solution Architecture for the Networking Solutions Group of LSI Corporation.
Raghu Kondapalli is director of technology focused on Strategic Planning and Solution Architecture for the Networking Solutions Group of LSI Corporation.
Kondapalli brings a rich experience and deep knowledge of the cloud-based, service provider and enterprise networking business, specifically in packet processing, switching and SoC architectures.
Most recently he was a founder and CTO of cloud-based video services company Cloud Grapes Inc., where he was the chief architect for the cloud-based video-as-a-service solution. Prior to Cloud Grapes, Kondapalli led technology and architecture teams at AppliedMicro, Marvell, Nokia and Nortel. Kondapalli has about 25 patent applications in process and has been a thought leader behind many technologies at the companies where he has worked.
Kondapalli received a bachelor’s degree in Electronics and Telecommunications from Osmania University in India and a master’s degree in Electrical Engineering from San Jose State University.
This is the second article in a two-part series. The first article, which discussed the drivers, benefits and trends of unified datacenter-carrier networks, and introduced SDN and NFV technology, is available here.
This article provides some examples of how SDN and NFV can be applied to various segments of a carrier network, and how the functions of a traditional carrier network can be offloaded to a virtualized datacenter to improve end-to-end performance.
Application of SDN and NFV to a Unified Datacenter-Carrier Network
With roots in voice, carrier networks are connection-oriented, while datacenter networks, with roots in data, utilize connectionless protocols. Carriers wanting to fully integrate its datacenter(s) will, therefore, need a common set of protocols. Possible choices include VxLAN (Virtual Extensible LAN) and NvGRE (Network Virtualization using Generic Routing Encapsulation), which are both extensible and scalable with the ability to support thousands of virtual machines (VMs), as well as tunneling protocols, such as IPSec, which can be used to establish end-to-end virtual private networks (VPNs).In addition to these well-known protocol-level techniques, network-level abstraction based on SDN similarly enables the integration of datacenter and carrier networks. Here are two examples.
Offloading of network control functions to a centralized datacenter using SDN
Control plane components, such as discovery and dissemination of network state, can be decoupled and executed in a centralized datacenter using commodity servers. Centralizing the control plane has the advantage of providing an end-to-end network state view, and enables the network operator to allocate hardware resource pools based on different application needs. Centralizing the control plane also enables the network operator to use standard APIs to monitor and manage the network, and to provision the network according to changing conditions, such as the number of active subscribers.
Offloading of network application software to a virtualized datacenter using SDN
SDN’s centralized control platform for managing hardware resources also supports the virtualization and execution of core applications in one or more datacenters. For a “software-on-demand” capability, for example, a network operator could designate core application software to run on any hardware platform in any datacenter that provides the required processing capacity. Or to provide LTE services in a certain city, the operator might program serving gateway (SGW) or mobility management entity (MME) software to run on a local platform. A major benefit of having network services being fully abstracted is that the operator need not manage the underlying hardware.
Application of SDN and NFV to Carrier Network Segments
Carrier networks are composed of access networks, transport or backhaul networks, and core networks as shown in Figure 6. Note the use of both connection-oriented (Time Division Multiplexing and Asynchronous Transfer Mode) and connectionless (IP) networks end-to-end across the infrastructure.Figure 7 shows a conceptual view of the SDN-based carrier network. Note how the hardware platform is decoupled from the software platform, and how this enables different cellular technologies to run as virtualized network elements concurrently and independently of any specific hardware platform.
Application of SDN and NFV to Core Networks
Mobile core networks consist of network elements that reside between connection-oriented radio access networks (RANs) and connectionless backbone networks, including the Internet, that employ packet switching. Core networks now also need to support a growing variety of cellular technologies, including 3G, LTE and 4G—all concurrently. The underlying core network functions, such as packet forwarding, as well as control tasks, such as mobility management, session handling and security, are implemented today using dedicated network elements.Consider, for example, an SGW that forwards packets and an MME that is responsible for activation or authentication in an LTE network. Because these functions are typically executed on common and proprietary hardware platforms, they are visible to one another, resulting in management, resource sharing and security problems. Abstraction with SDN enables the use of commodity hardware, while also mitigating the management, resource sharing and security issues.
Another example is shown in Figure 8. In this example, dedicated application software, which implements network functions for each dedicated core network element like MME or Gateway and Serving GPRS Support Nodes (GGSN and SGSN), can be virtualized and centralized with SDN to run in a private cloud, on virtualized commercial server platforms, or on multi-vendor, non-proprietary hardware.
Application of SDN and NFV to Carrier Access Networks
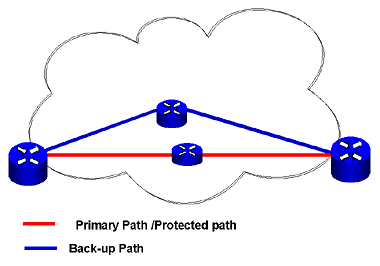
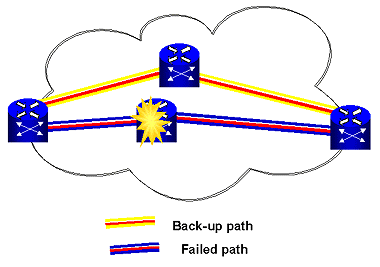
Subscribers interface with the carrier network via basestation nodes in the RAN, as shown in Figure 6. Owing to the explosion in mobile device adoption and mobile data usage worldwide, the RAN must now be optimized to address these challenges:- rapid increase in the number of more closely-spaced base stations needed to cover a given area with LTE eNodeB deployments
- relatively low basestation utilization with relatively high power consumption
- similarly low utilization of RF bandwidth resulting from RF interference and limited network capacity in a multi-standard environment

Figure 10 shows an implementation of such a “Cloud-based RAN” (C-RAN) architecture that has been proposed by China Mobile (CMCC). The wireless remote radios connect to a cloud-based, virtualized basestation cluster, which can be implemented using SDN running on heterogeneous hardware processors.

Application of SDN and NFV to Carrier Transport Networks
The transport network in a wireless infrastructure serves as the backhaul network connecting the basestations in the access network to the core network. Transport networks can utilize many different technologies, including SONET, TDM, carrier Ethernet and IP, each of which exhibits different operating characteristics. For example, TDM has a simple operational model characterized by static routes and traffic flows across the network’s centralized control. By contrast, the IP network operational model routes traffic packet-by-packet across the network under distributed network control.SDN is able to combine these different networking technologies in a way that leverages their respective strengths; in the example above, the simplicity of static network routing is combined with the flexibility and economic advantages of IP. This is possible because SDN decouples the network control and traffic-forwarding functions, thereby eliminating any interdependencies. For this reason, a distributed transport network element is able to support both static routes and dynamic traffic flows.
Summary
The telecommunications industry today, fueled by exploding growth in mobile subscribers and data usage, is undergoing an unprecedented transformation. As a result, service providers are under enormous pressure to deploy new value-added services while lowering costs to remain competitive. To achieve these objectives, carriers are integrating datacenters into their networks to create a more versatile and affordable unified datacenter-carrier network model.
Service providers also need to increase average revenue per user (ARPU) while reducing capital and operational expenditures through hardware consolidation, network resource optimization and ease-of-service deployment. Virtualization is a proven technology that has been adopted universally in datacenters to enhance resource utilization and scalability. By extending virtualization principles to the carrier infrastructure, service providers can optimize the unified datacenter-carrier network end-to-end and top-to-bottom.
Software-defined Networking and Network Function Virtualization enable this versatility in all three segments of a carrier network. SDN enables network functions and applications to leverage virtualized datacenter resources, while a combination of SDN and NFV enables carriers to deploy and scale innovative services more cost-effectively than ever before.
Raghu Kondapalli is director of technology focused on Strategic Planning and Solution Architecture for the Networking Solutions Group of LSI Corporation.Kondapalli brings a rich experience and deep knowledge of the cloud-based, service provider and enterprise networking business, specifically in packet processing, switching and SoC architectures.
Most recently he was a founder and CTO of cloud-based video services company Cloud Grapes Inc., where he was the chief architect for the cloud-based video-as-a-service solution. Prior to Cloud Grapes, Kondapalli led technology and architecture teams at AppliedMicro, Marvell, Nokia and Nortel. Kondapalli has about 25 patent applications in process and has been a thought leader behind many technologies at the companies where he has worked.
Kondapalli received a bachelor’s degree in Electronics and Telecommunications from Osmania University in India and a master’s degree in Electrical Engineering from San Jose State University.