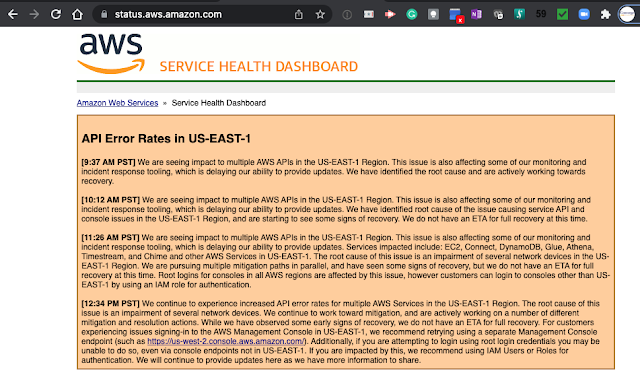
Rogers experienced a widespread network outage beginning on Friday morning and impacting Quebec and Ontario primarily, as well as other linked services nationwide. The Rogers outage led to cascading effects at banks, credit card processing, and online businesses.
On Saturday, Rogers reported service restoration to the majority of its users.
Tony Staffieri, the president and CEO of Rogers, stated "We now believe we’ve narrowed the cause to a network system failure following a maintenance update in our core network, which caused some of our routers to malfunction early Friday morning. We disconnected the specific equipment and redirected traffic, which allowed our network and services to come back online over time as we managed traffic volumes returning to normal levels. We know how much our customers rely on our networks and I sincerely apologize. We’re particularly troubled that some customers could not reach emergency services and we are addressing the issue as an urgent priority. We will proactively credit all customers automatically for yesterday’s outage. This credit will be automatically applied to your account and no action is required from you."


Rogers launch Canada’s first commercial 5G standalone network
 Rogers Communications a has launched the first commercial 5G standalone (SA) network in Canada, turning on the next-generation service after completing the rollout of Canada’s first national standalone 5G core and the country’s first 5G standalone device certification. Rogers said its 5G SA Core network has been built from the ground up based on the latest cloud native technologies, enabling more advanced wireless capabilities like ultra-low...
Rogers Communications a has launched the first commercial 5G standalone (SA) network in Canada, turning on the next-generation service after completing the rollout of Canada’s first national standalone 5G core and the country’s first 5G standalone device certification. Rogers said its 5G SA Core network has been built from the ground up based on the latest cloud native technologies, enabling more advanced wireless capabilities like ultra-low...
Rogers + Shaw merger to reshape Canadian market